





by
, , , , and


Mach. Learn. Knowl. Extr. 2023, 5(3), 1023-1035; https://doi.org/10.3390/make5030053 - 07 Aug 2023
Abstract
This study examines the ethical issues surrounding the use of Artificial Intelligence (AI) in healthcare, specifically nursing, under the European General Data Protection Regulation (GDPR). The analysis delves into how GDPR applies to healthcare AI projects, encompassing data collection and decision-making stages, to
[...] Read more.
This study examines the ethical issues surrounding the use of Artificial Intelligence (AI) in healthcare, specifically nursing, under the European General Data Protection Regulation (GDPR). The analysis delves into how GDPR applies to healthcare AI projects, encompassing data collection and decision-making stages, to reveal the ethical implications at each step. A comprehensive review of the literature categorizes research investigations into three main categories: Ethical Considerations in AI; Practical Challenges and Solutions in AI Integration; and Legal and Policy Implications in AI. The analysis uncovers a significant research deficit in this field, with a particular focus on data owner rights and AI ethics within GDPR compliance. To address this gap, the study proposes new case studies that emphasize the importance of comprehending data owner rights and establishing ethical norms for AI use in medical applications, especially in nursing. This review makes a valuable contribution to the AI ethics debate and assists nursing and healthcare professionals in developing ethical AI practices. The insights provided help stakeholders navigate the intricate terrain of data protection, ethical considerations, and regulatory compliance in AI-driven healthcare. Lastly, the study introduces a case study of a real AI health-tech project named SENSOMATT, spotlighting GDPR and privacy issues.
Full article
(This article belongs to the Topic Secure Applications with Blockchain and Artificial Intelligence)
►
Show Figures
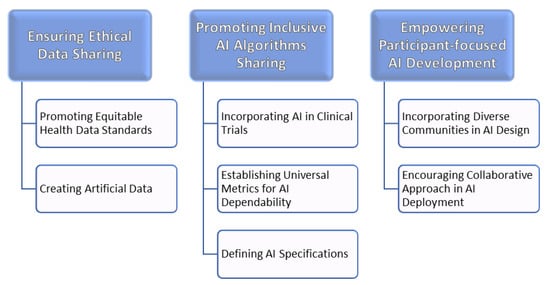
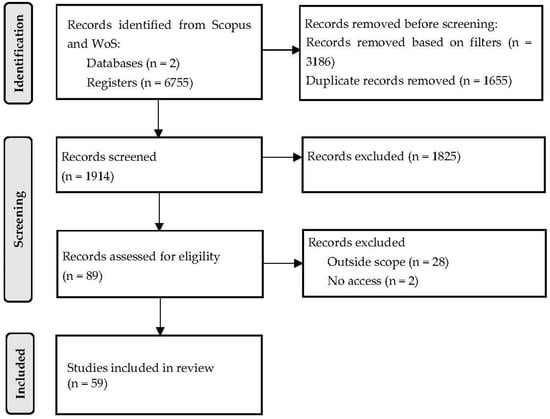
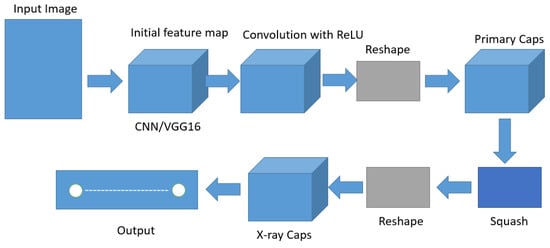
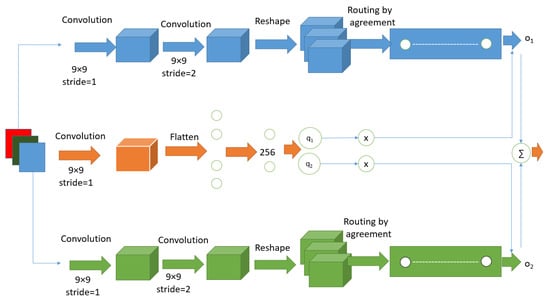
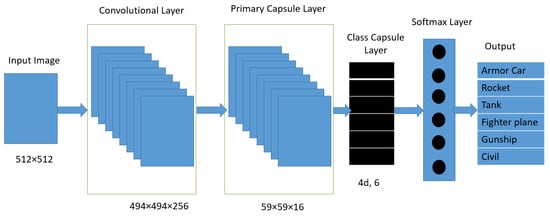
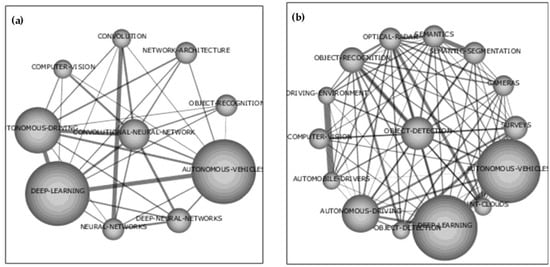
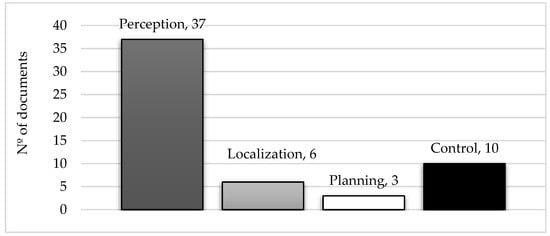
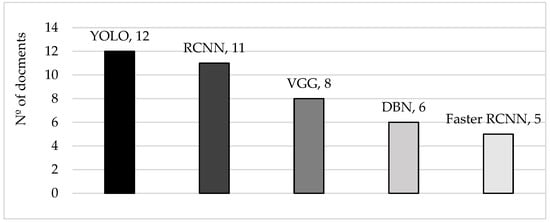
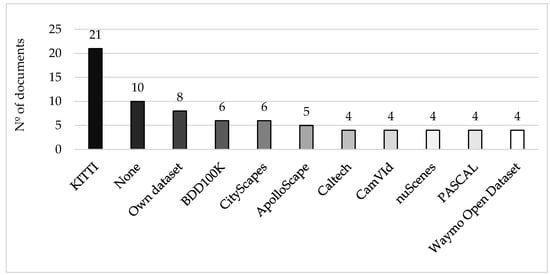
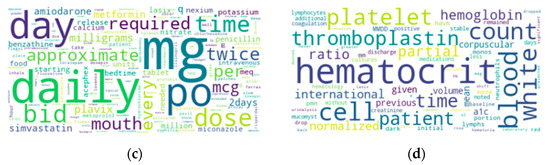
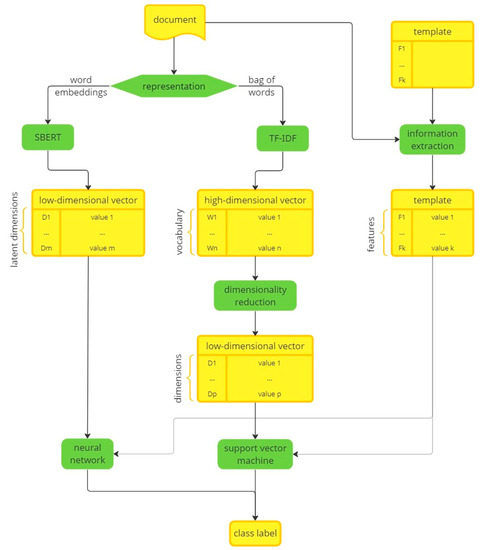
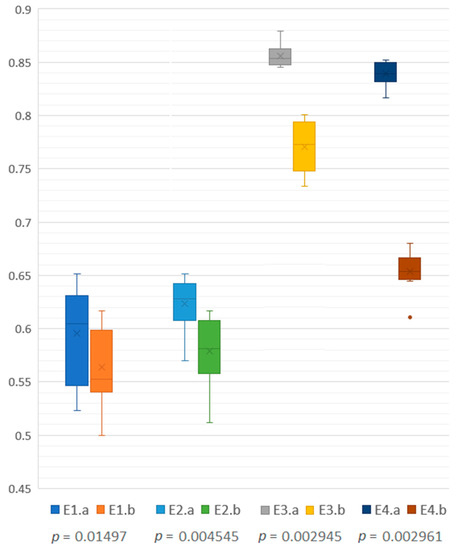
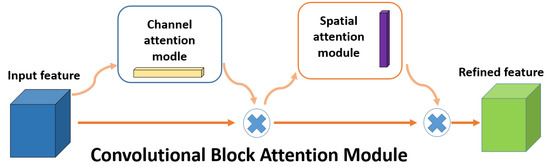
Figure 1
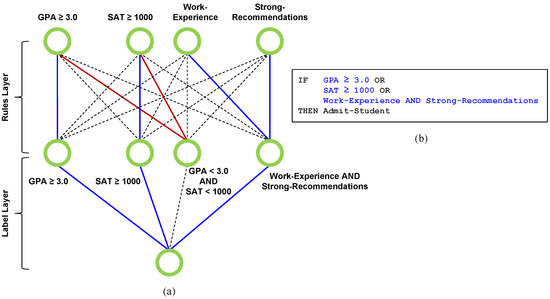
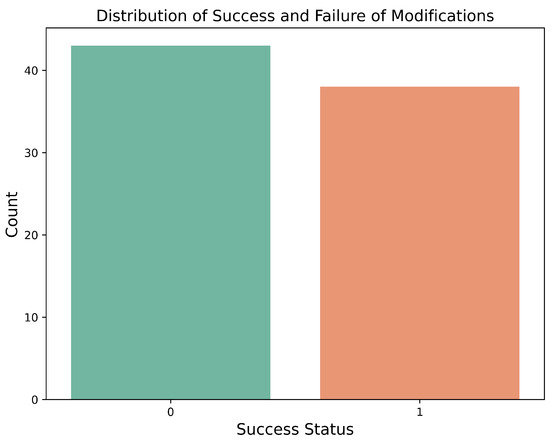
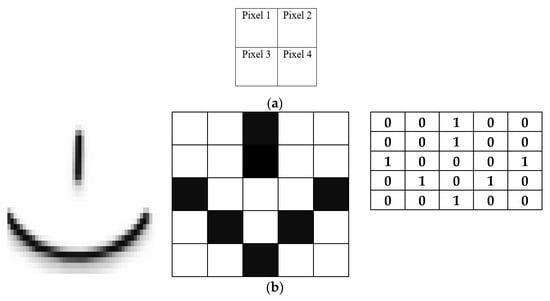
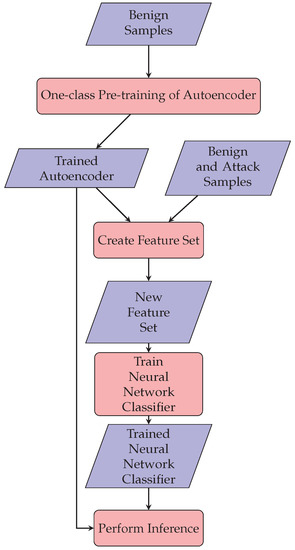








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
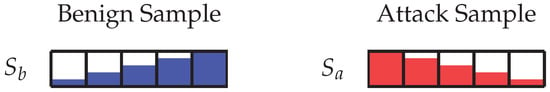{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
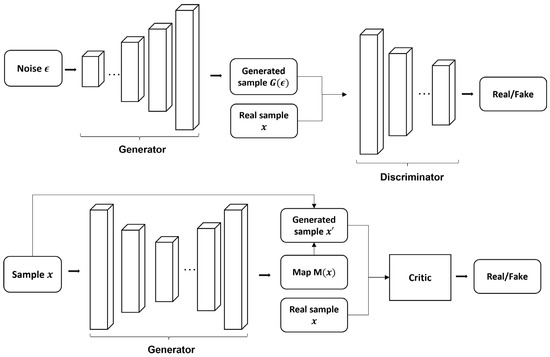{kind=link}
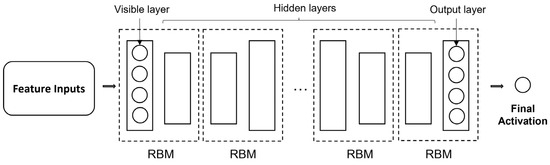{kind=link}
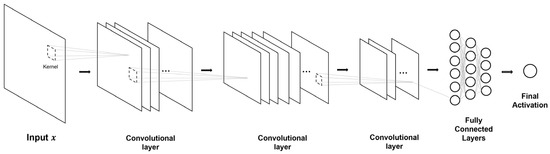{kind=link}
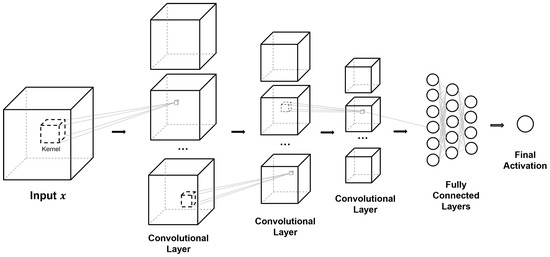{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}