





Data 2023, 8(8), 129; https://doi.org/10.3390/data8080129 - 08 Aug 2023
Abstract
►
Show Figures
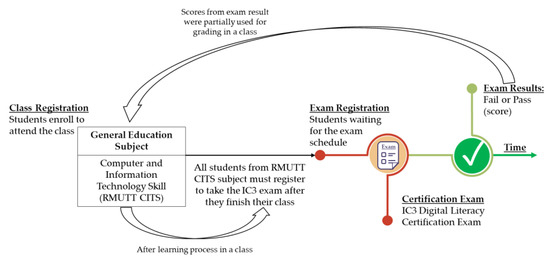
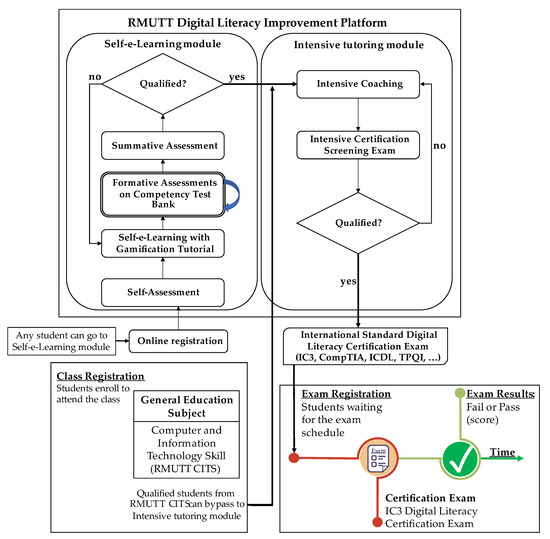
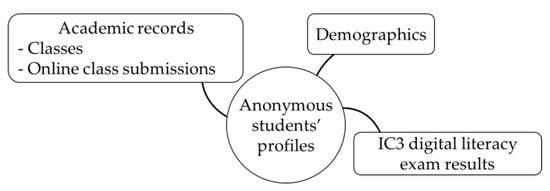
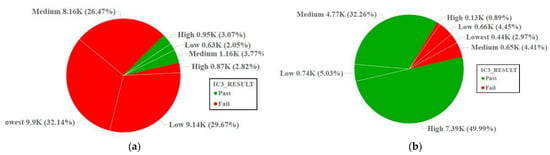
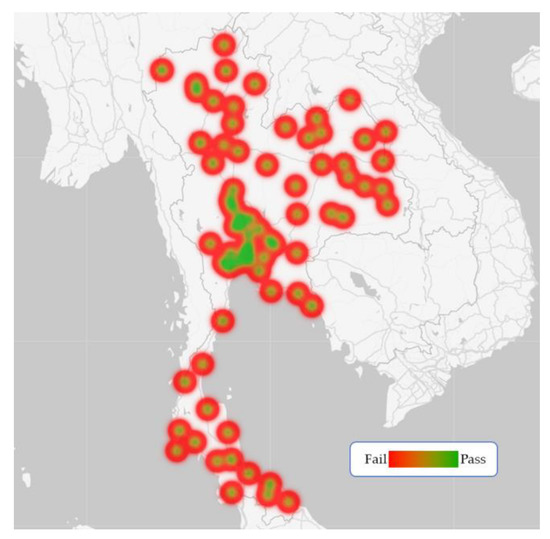
This article presents a dataset containing messages from the Digital Teaching Assistant (DTA) system, which records the results from the automatic verification of students’ solutions to unique programming exercises of 11 various types. These results are automatically generated by the system, which automates
[...] Read more.
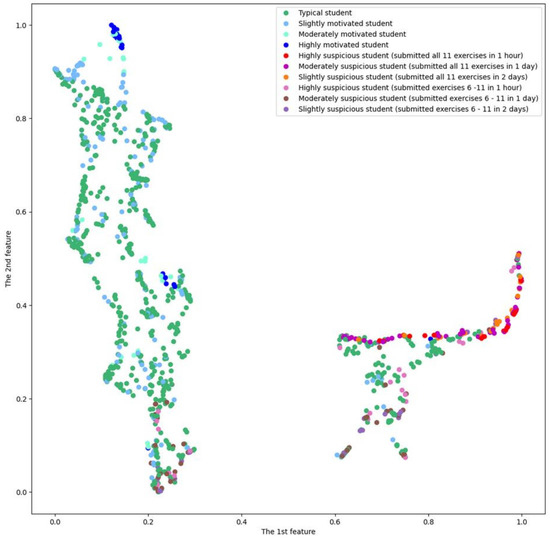
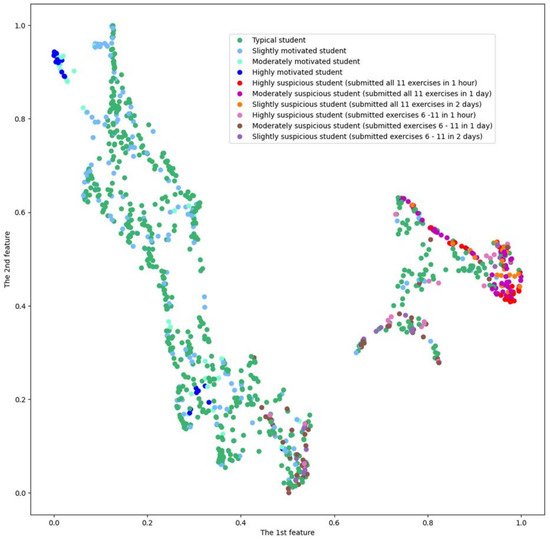
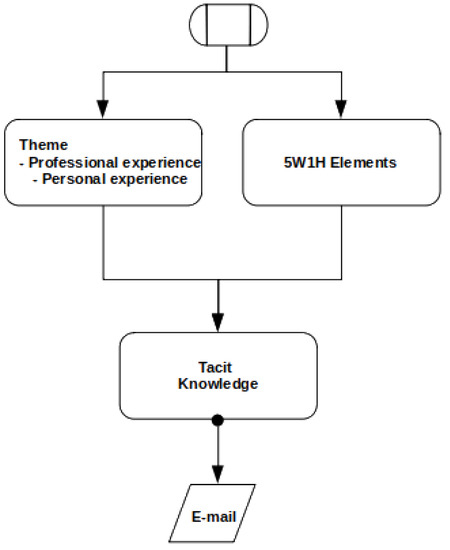
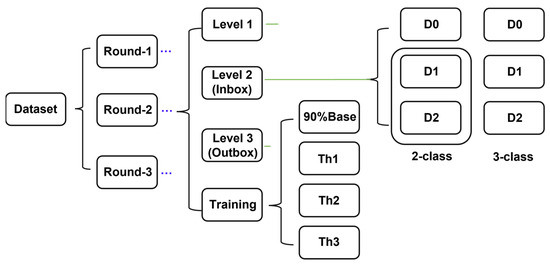
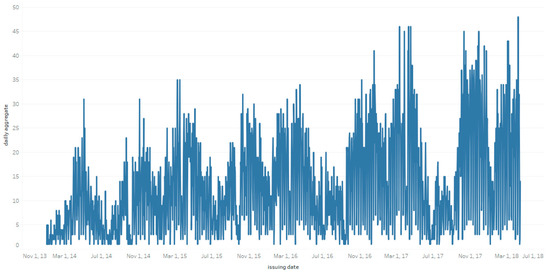
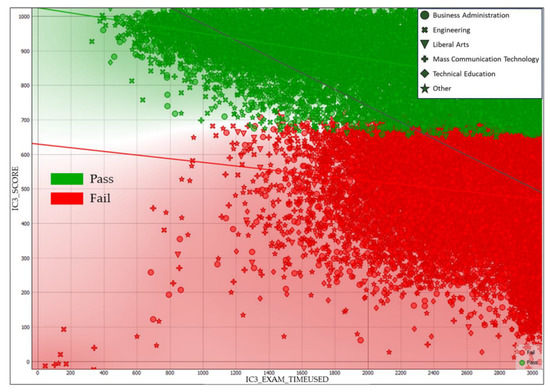
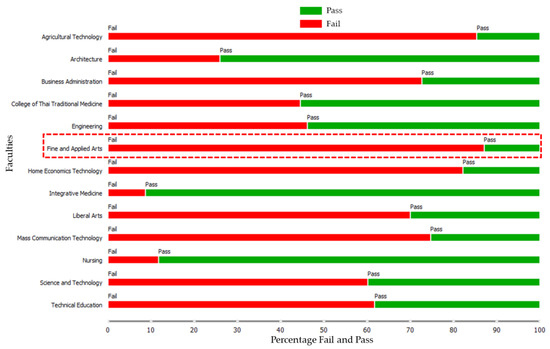
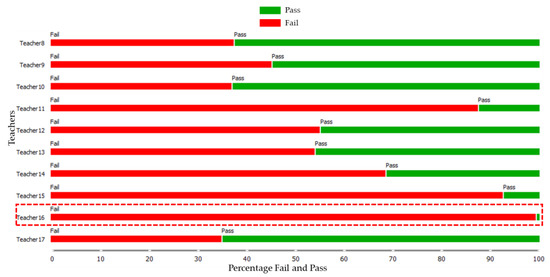
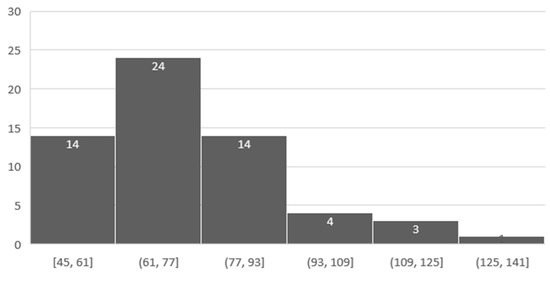
This article presents a dataset containing messages from the Digital Teaching Assistant (DTA) system, which records the results from the automatic verification of students’ solutions to unique programming exercises of 11 various types. These results are automatically generated by the system, which automates a massive Python programming course at MIREA—Russian Technological University (RTU MIREA). The DTA system is trained to distinguish between approaches to solve programming exercises, as well as to identify correct and incorrect solutions, using intelligent algorithms responsible for analyzing the source code in the DTA system using vector representations of programs based on Markov chains, calculating pairwise Jensen–Shannon distances for programs and using a hierarchical clustering algorithm to detect high-level approaches used by students in solving unique programming exercises. In the process of learning, each student must correctly solve 11 unique exercises in order to receive admission to the intermediate certification in the form of a test. In addition, a motivated student may try to find additional approaches to solve exercises they have already solved. At the same time, not all students are able or willing to solve the 11 unique exercises proposed to them; some will resort to outside help in solving all or part of the exercises. Since all information about the interactions of the students with the DTA system is recorded, it is possible to identify different types of students. First of all, the students can be classified into 2 classes: those who failed to solve 11 exercises and those who received admission to the intermediate certification in the form of a test, having solved the 11 unique exercises correctly. However, it is possible to identify classes of typical, motivated and suspicious students among the latter group based on the proposed dataset. The proposed dataset can be used to develop regression models that will predict outbursts of student activity when interacting with the DTA system, to solve clustering problems, to identify groups of students with a similar behavior model in the learning process and to develop intelligent data classifiers that predict the students’ behavior model and draw appropriate conclusions, not only at the end of the learning process but also during the course of it in order to motivate all students, even those who are classified as suspicious, to visualize the results of the learning process using various tools.
Full article

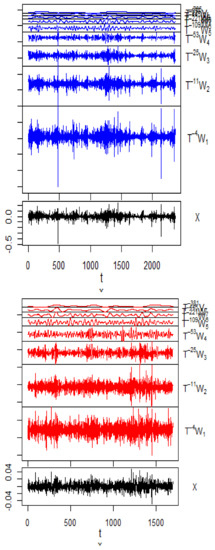
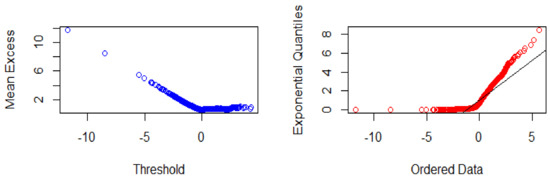
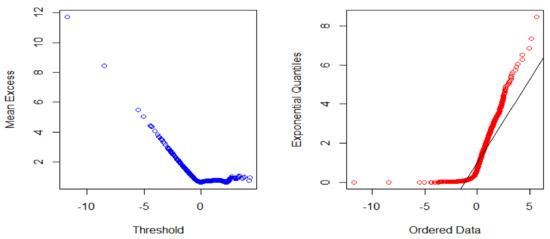
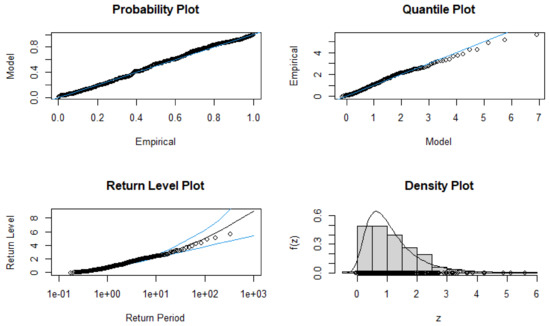
Figure 1























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}