






Big Data Cogn. Comput. 2023, 7(3), 139; https://doi.org/10.3390/bdcc7030139 - 08 Aug 2023
Abstract
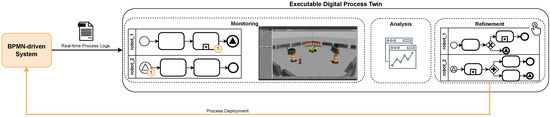
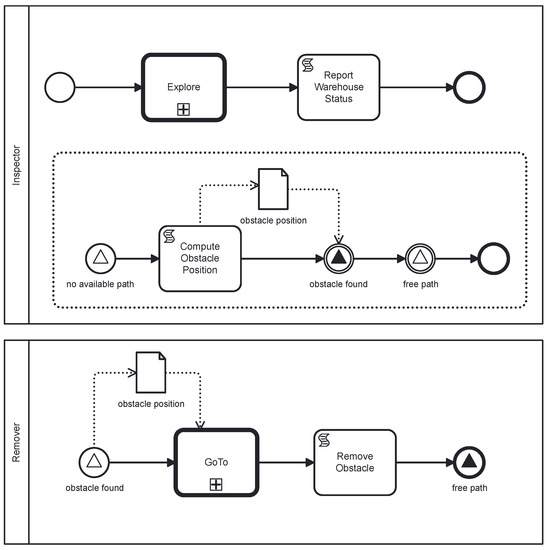
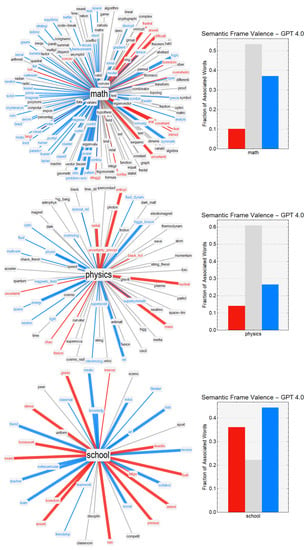
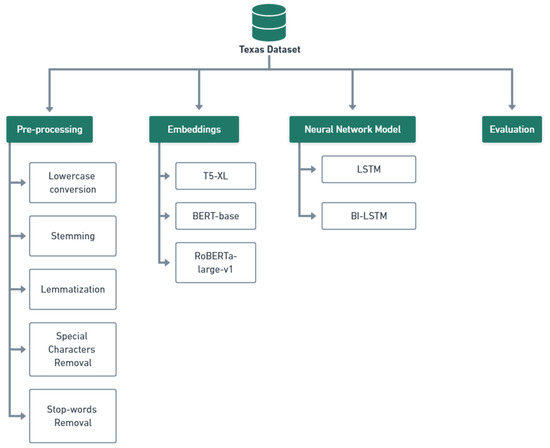
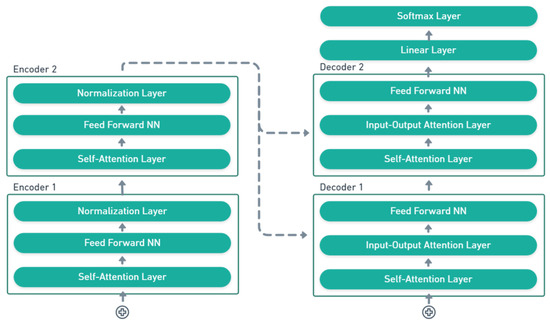
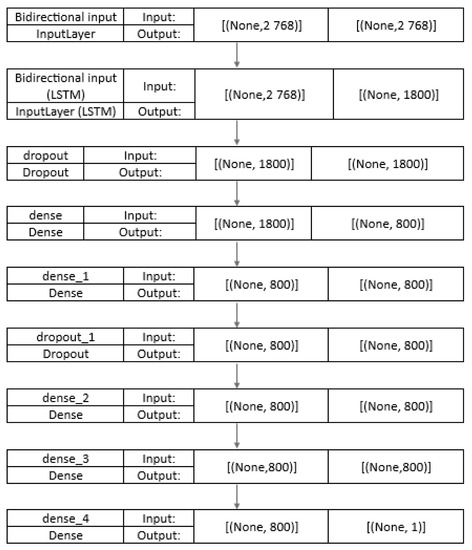
The development of process-driven systems and the advancements in digital twins have led to the birth of new ways of monitoring and analyzing systems, i.e., digital process twins. Specifically, a digital process twin can allow the monitoring of system behavior and the analysis
[...] Read more.
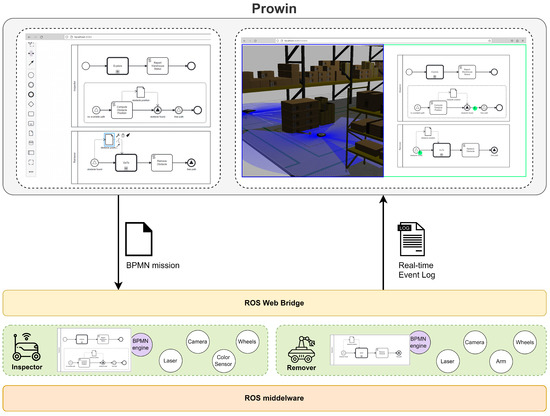
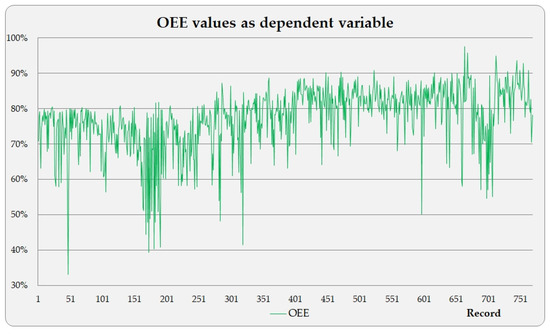
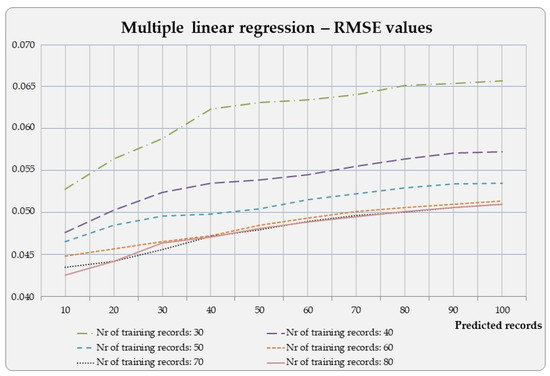
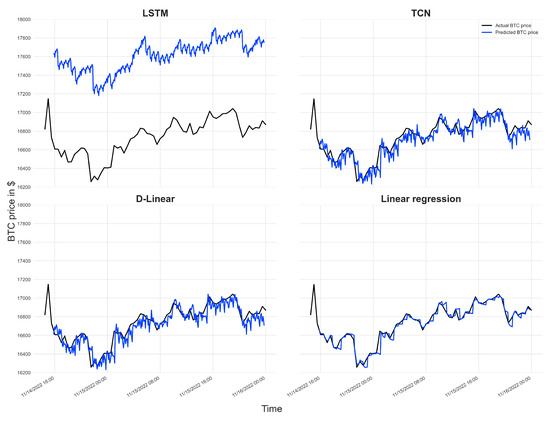
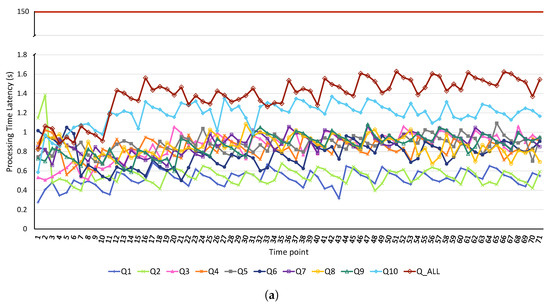
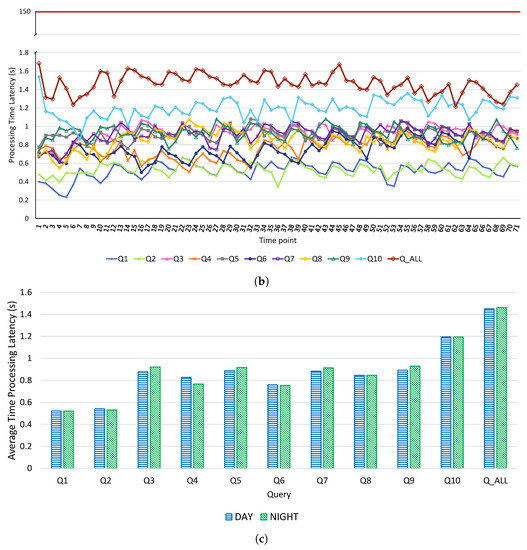
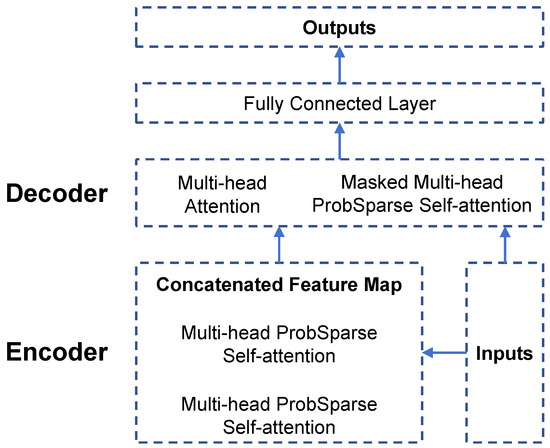
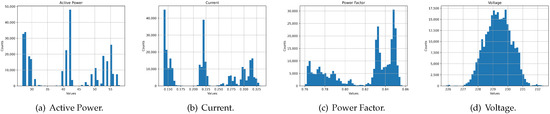
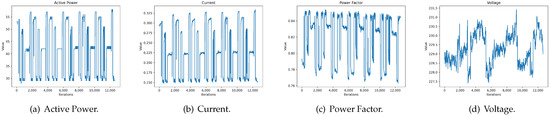
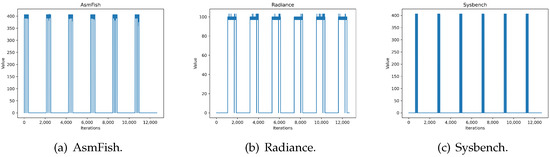
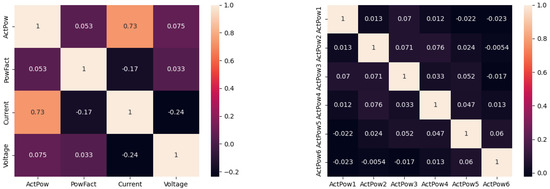
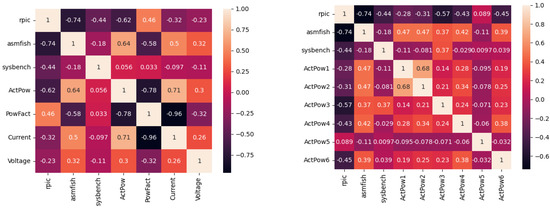
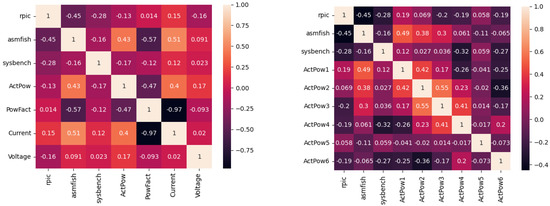
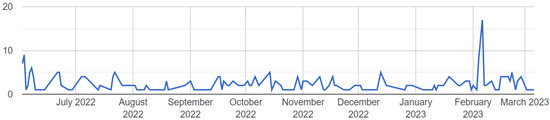
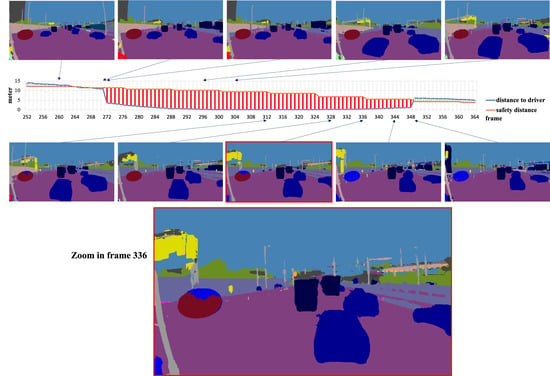
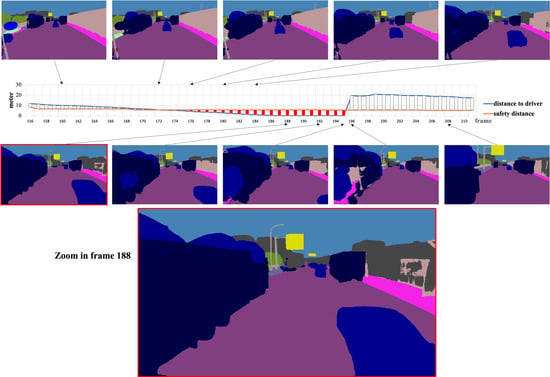
The development of process-driven systems and the advancements in digital twins have led to the birth of new ways of monitoring and analyzing systems, i.e., digital process twins. Specifically, a digital process twin can allow the monitoring of system behavior and the analysis of the execution status to improve the whole system. However, the concept of the digital process twin is still theoretical, and process-driven systems cannot really benefit from them. In this regard, this work discusses how to effectively exploit a digital process twin and proposes an implementation that combines the monitoring, refinement, and enactment of system behavior. We demonstrated the proposed solution in a multi-robot scenario.
Full article
(This article belongs to the Special Issue Digital Twins for Complex Systems)
►
Show Figures
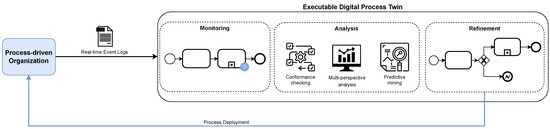
Figure 1

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}